It is always fun to start a new project. Fresh and simple classes, clear boundaries, clear architecture – everything is logical and beautiful. New functionality is added quickly and easily.
Time passes, the project grows and new requirements keep arriving. So the day comes when you find something bad in the code. Someone cut a corner and made a small glitch. It even happens that you yourself do something in a hurry, honestly inserting “still todo” into the code – simply because this functionality is needed for the upcoming release, and there is no time to do everything correctly. “We know it’s there, but we will definitely fix after this release, but now we need to issue this version,” is usually said at that time. It’s a technical debt.
However, there is nothing more permanent than temporary! Usually it happens that the technical debt is only increasing. Just as a loan in a bank requires interest payments, the presence of technical debt takes its interest. We pay for this with the increasing complexity of making changes, the increasing non-obviousness and illogicality of the model, the disappearing enthusiasm of the team.
Then at a certain point, it becomes clear: The story repeated itself and we have in our hands the next “big ball of mud”. What to do and can this be avoided?
Nowadays, many see the answer in microservice architecture. It has clear physical boundaries, which will not allow cutting corners. Not at least in the way it would have been done in the case of a monolith system.
But the microservices approach has its price, stemming from the distributed nature of such a system. Where everything happened before in one process, we now have inter-server interaction. Which comes with data transmission over the network, as well as serialization/deserialization of data. Where there used to be transactional integrity, now there is event consistency. Instead of synchronous calls, with a clear result, now there is an asynchronous call to several nodes, each of which may return with an error or might give a timeout. And many other issues that are not obvious at first glance, but will automatically pop up because we are using distributed systems. Even when starting a new project, it may be difficult or even impossible for us to properly divide the future system into microservices, simply because we do not know how the system will develop. And trying to think about the architecture in advance is usually unproductive.
In general, when developing a new project from scratch based on microservices, the feeling of shooting flies with a cannon does not leave. The system still does not look so complicated as to apply division into subsystems.
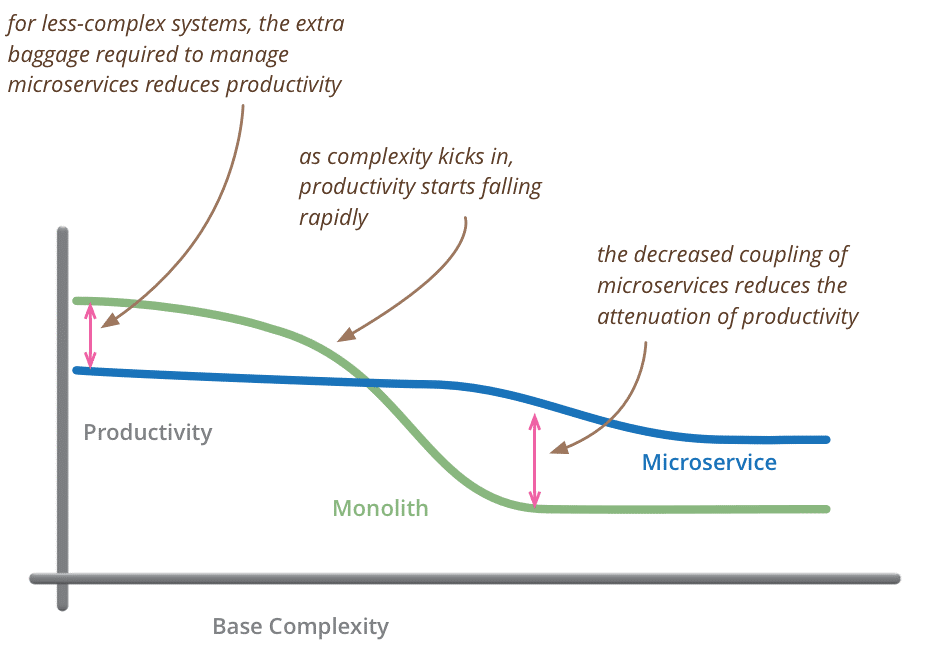
Obviously, when the system starts to grow there is a moment when the price of microservices pays off. It will be reducing the costs of decreasing the productivity of the team when the system becomes more complex. Martin Fowler (Martin Fowler) well illustrated this in his article Microservice Premium: